はじめに
ほ!!! nikkieです
正規表現について、新しく知ったことがありました。
\p{L}ってなんだと思います?
目次
- はじめに
- 目次
- MDNより「Unicode 文字クラスエスケープ」
- 「Unicode 文字クラスエスケープ」中の例
- Unicode Technical Standard #18 を参照
- 『正規表現辞典』を紐解く
- Pythonではregex
- 終わりに
- P.S. そもそもどこで\pを見かけた?
MDNより「Unicode 文字クラスエスケープ」
Unicode 文字クラスエスケープは文字クラスエスケープの一種で、Unicode プロパティで指定された一連の文字に一致します。
文字クラスエスケープとは、正規表現の\dや\w!
これは見たことあります。
文字クラスエスケープは、文字の集合を表すエスケープシーケンスです。
文字クラスエスケープ: \d, \D, \w, \W, \s, \S - JavaScript | MDN
つまり\pや\Pは文字の集合を表すエスケープシーケンスというわけですね。
「Unicode 文字クラスエスケープ」のドキュメントは次のように続きます。
これは Unicode 対応モードでのみ対応しています。
これはuフラグのことですね1。
正規表現 - JavaScript | MDN
解説によると
すべての Unicode 文字には、それを記述する一連のプロパティがあります。
例えば、a という文字では、General_Category プロパティが Lowercase_Letter の値であり、Script プロパティが Latn の値です。
な、なんだってー! プロパティなんてものがあったのか
例えば、a は \p{Lowercase_Letter}(General_Category プロパティ名はオプション)と、\p{Script=Latn} によって一致させることができます。
\Pは\pの否定です
「Unicode 文字クラスエスケープ」中の例
「一般カテゴリー」2に\p{L}の例があります。
上で引いた「General_Category プロパティ名はオプション」を補足するような形になっています。
/\p{L}/gu/\p{General_Category=Letter}/gu(General_Categoryというプロパティ名を書いた)/\p{Letter}/gu(General_Categoryを省略)
ブラウザ(Firefox)の開発ツールのコンソールで実行します。
const story = "It's the Cheshire Cat: now I shall have somebody to talk to."; story.match(/\p{L}/gu);
Array(46) [ "I", "t", "s", "t", "h", "e", "C", "h", "e", "s", … ]
空白文字や記号を除いた文字にマッチしました!
story.match(/\p{General_Category=Letter}/gu);のように書き換えても同じ結果です。
Unicode Technical Standard #18 を参照
「Unicode Technical Standard #18 Unicode Regular Expressions」に「General Category Property」があります(1.2.5)3。
https://unicode.org/reports/tr18/#General_Category_Property
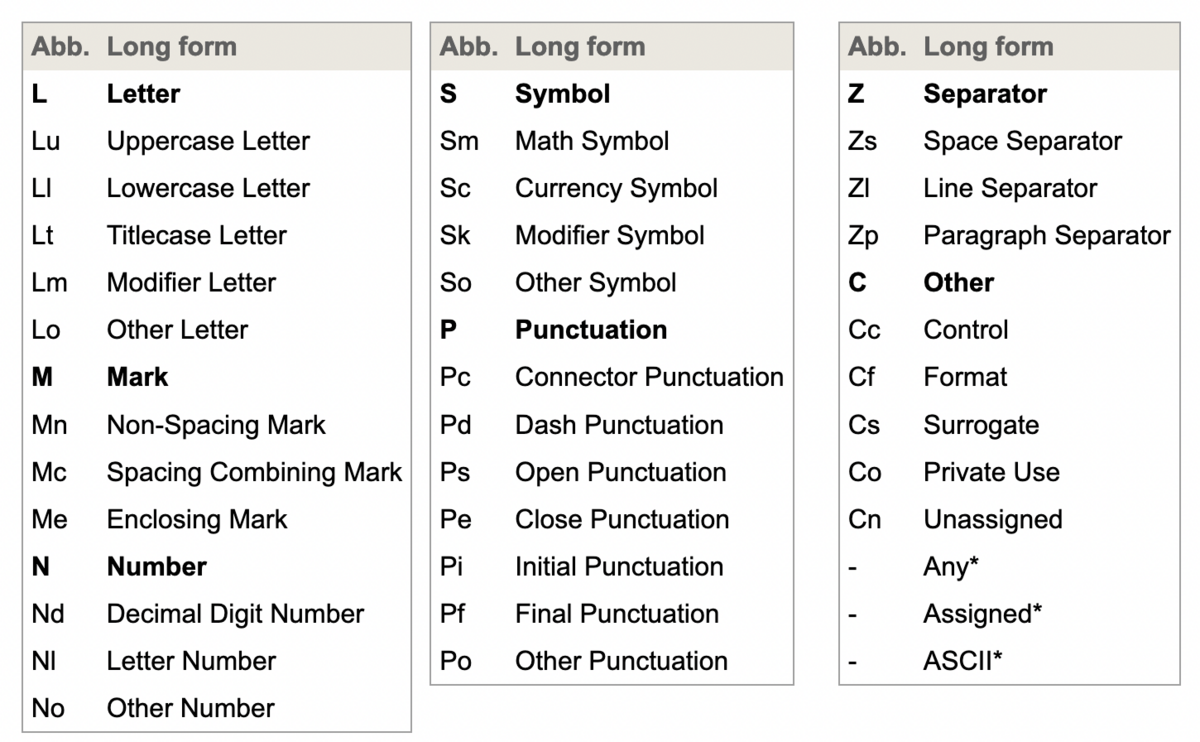
この表には、プロパティの値とその短縮名(Long formとAbb.)が記載されています。
- Letter(短縮名はL)
- Uppercase Letter(短縮名はLu)
大文字小文字やスペース、アンダースコアの有無など表記が揺れても、指す文字の集合としては同じとのことです。
any of the following should be equivalent: \p{Lu}, \p{lu}, \p{uppercase letter}, \p{Uppercase Letter}, \p{Uppercase_Letter}, and \p{uppercaseletter}
『正規表現辞典』を紐解く
03-04-06 \p{...}、\P{...} Unicodeプロパティに基づく条件に合致する文字にマッチ
例が面白いなと思いました。
\p{Lu}(Uppercase Letter)は、例えば全角のGにもマッチ\p{InHiragana}でひらがなにマッチ
"半角のG 全角のG".match(/\p{Lu}/gu);
Array [ "G", "G" ]
"半角のG 全角のG".match(/\p{InHiragana}/gu);は
Uncaught SyntaxError: invalid property name in regular expression
でした。未サポートなんですかね?
Pythonではregex
標準ライブラリreの拡張。
Unicode codepoint propertiesもサポートしています!
>>> regex.findall(r"\p{Lu}", "半角のG 全角のG") ['G', 'G'] >>> regex.findall(r"\p{InHiragana}", "半角のG 全角のG") ['の', 'の']
Python 3.10.9、regex 2024.4.16で動かしています
終わりに
\p{}や\P{}で{}中にUnicode文字のプロパティを指定できる\dのように文字の集合を指定しているということ- 例えば
\p{Lu}でUppercase Letterを指定。これは半角だけでなく全角などにもマッチする
- 例えば
- JavaScriptではunicodeフラグを指定した正規表現リテラル
InHiraganaなど、Unicode文字クラスエスケープで指定するのは便利そうな気がします。

P.S. そもそもどこで\pを見かけた?
VS Codeの実装を覗いていて!4
https://github.com/microsoft/vscode/blob/1.88.1/src/vs/editor/contrib/linesOperations/browser/linesOperations.ts#L1135
public static titleBoundary = new BackwardsCompatibleRegExp('(^|[^\\p{L}\\p{N}\']|((^|\\P{L})\'))\\p{L}', 'gmu');
JavaScriptの正規表現リテラルには、本文で紹介した/\p{Lu}/guの記法の他に、RegExpオブジェクトを使う方法があります5。
後者の方法ではバックスラッシュを使って特殊文字をエスケープします。
なので、'\\p'となると理解しました。
ref: 正規表現 - JavaScript | MDN
"半角のG 全角のG".match(new RegExp("\\p{Lu}", "gu"));
Array [ "G", "G" ]