はじめに
頑張れば、何かがあるって、信じてる。nikkieです。
2019年12月末から自然言語処理のネタで毎週1本ブログを書いています。
そこで直近1クール(2020年3月末まで)は、自然言語処理のネタで毎週1本ブログを書くことにします。
今回で最終回を迎えます。
前回3/22の取り組みで「BERTの学習が遅いために、テキストから特徴量を作るのに使われる」ということを体感しました。
その続きとしてBERTで特徴量を作るのを試しました。
目次
- はじめに
- 目次
- 動作環境
- 作ったスクリプトたち
- BERTで特徴量を作るにあたっての参考資料
- 1.transformersのサンプルコードを理解する
- 2.BERTを使ってBBCニュースのテキストを特徴量に変換する
- 3.BERTで作った特徴量をもとに分類器を作成
- 感想
動作環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G3020 $ python -V # venvによる仮想環境を利用 Python 3.7.3 $ pip list # 手動で入れたものを抜粋して記載 (3/22の環境に追加) ipython 7.13.0 numpy 1.18.1 scikit-learn 0.22.2.post1 tensorflow 2.1.0 transformers 2.5.1
作ったスクリプトたち
ファイル配置
. ├── bbc-text.csv # 原データ(BBCニューステキスト。5カテゴリ) ├── bert_feature.py ├── bert-feature.csv ├── env # 仮想環境 ├── preprocess.py # 前処理 ├── preprocessed-bbc.csv └── train_from_bert_feature.py
これらは以下の関係にあります。
preprocess.pyでbbc-text.csvのテキストを前処理(トークン化)し、preprocessed-bbc.csvとして保存(詳しくは前回の記事を参照)bert_feature.pyでpreprocessed-bbc.csvのテキストを特徴量(小数値)に変換し、bert-feature.csvとして保存train_from_bert_feature.pyでbert-feature.csvを用いていくつかの分類器を学習
BERTで特徴量を作るにあたっての参考資料
やりたかったことに近かった以下の記事を参考にしました(「ツイートを文章ベクトルに変換する」の部分)。
記事ではPyTorchで実装されていますが、
BertTokenizerでテキストをIDに変換1BertModelの__call__を呼び出し、IDを変換し、文章ベクトルを取り出す
という手順になるようです。
ですが、BertTokenizerとBertModel(TensorFlowならTFBertModel)を使った他のコードを見てもいまいちピンとこず。。
そんな中で参考になったのが以下の記事(☆)。
DistilBERT(?)についての記事ですが、入出力についてはBERTにも該当するようです。
BERTで特徴量を作るには、BERTのTokenizerやモデルへの入出力の意味を掴むのが早道でした。
たくさんある図を参考にして手を動かしていきました。
記事(☆)に登場するコードの全容はこちら
1.transformersのサンプルコードを理解する
前回「動いた!」と喜んだサンプルコードですが、これが何をしているかの理解が必要でした。
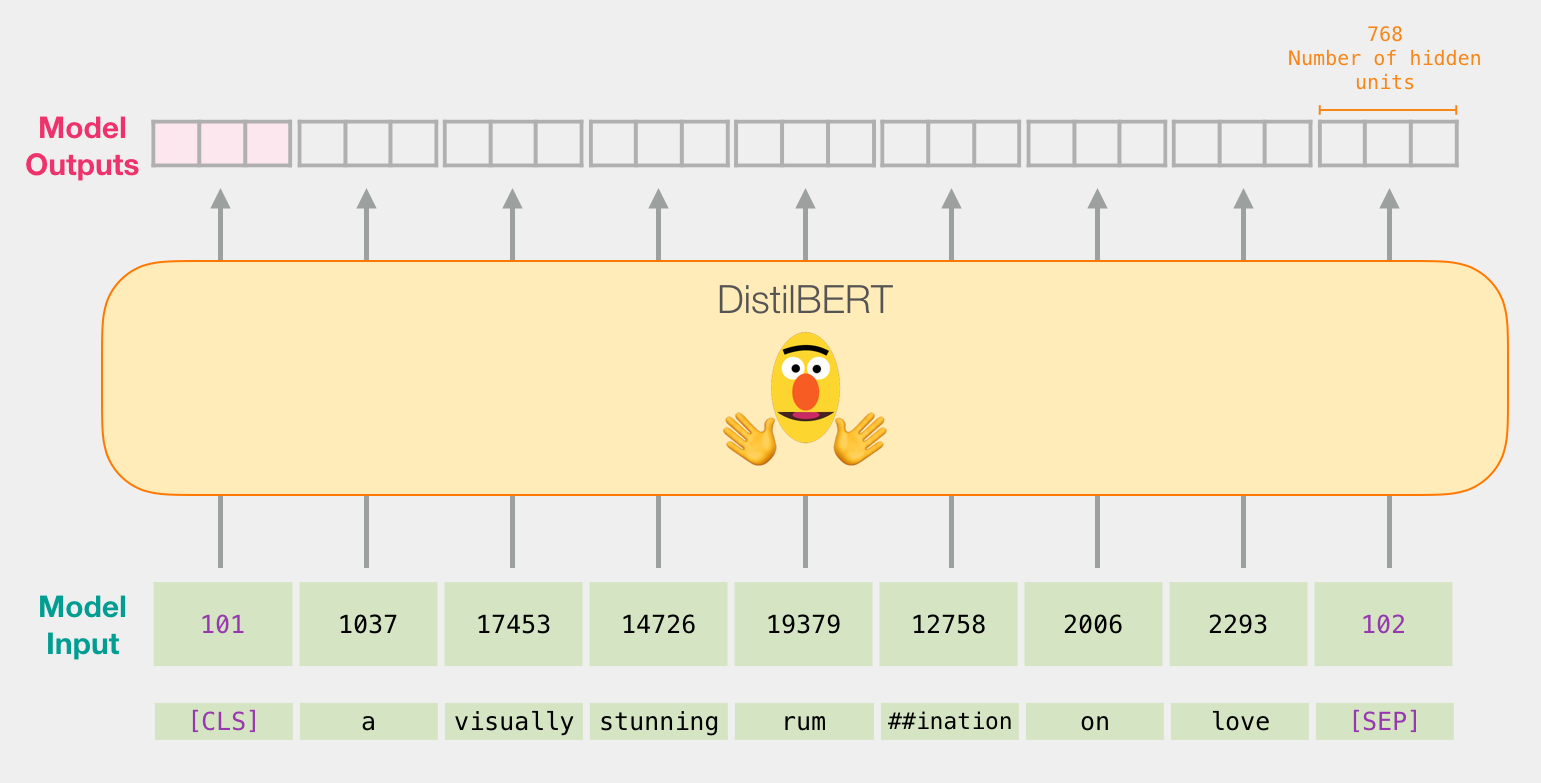
In [1]: import tensorflow as tf In [2]: from transformers import BertTokenizer, TFBertModel In [3]: tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') In [4]: model = TFBertModel.from_pretrained('bert-base-uncased')
BertTokenizerを使ってテキストを対応するIDの並びに変える
BertTokenizerのencodeメソッド2にテキスト(str)を渡すと、自然数からなるリストが返ります3。
Converts a string in a sequence of ids (integer), using the tokenizer and vocabulary.
この自然数はトークンに対応するIDです。
transformersのドキュメントではInput IDと呼ばれています。
In [5]: encoded = tokenizer.encode("Hello, my dog is cute", add_special_tokens=True) In [6]: encoded Out[6]: [101, 7592, 1010, 2026, 3899, 2003, 10140, 102]
encodeメソッドのadd_special_tokens=Trueという指定により、文頭や文末を表す[CLS]や[SEP]に対応するIDも付与されています。
TFBertModelにIDの並びを入力し、出力を得る
TFBertModelの__call__メソッドを呼び出して、出力を得ます4。
ここで、__call__メソッドへの入力はtf.Tensorにする必要があります。
encodeメソッドの出力を直接与えられません。
tf.constantで変換して渡す必要があります。
また、入力するtf.Tensorの形式は(batch_size, sequence_length)とする必要があります。
この例の場合は1つの文だけなので、batch_sizeが1、sequence_lengthはlen(encoded)と同じ8になります。
(batch_size, sequence_length)という2次のテンソルにするために、tf.constant([encoded])という書き方5が必要でした。
In [7]: input_ids = tf.constant([encoded]) In [8]: input_ids.shape Out[8]: TensorShape([1, 8]) In [10]: outputs = model(input_ids)
TFBertModelの出力から、特徴量を取り出す
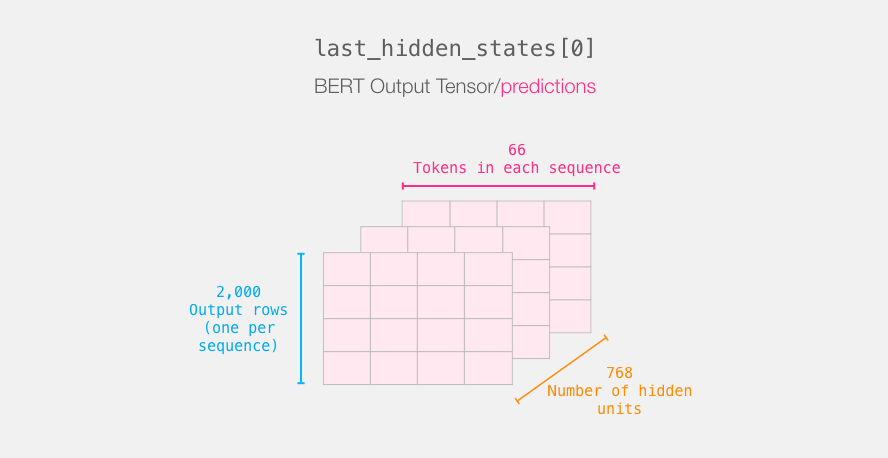
__call__メソッドで得たoutputsですが、これは長さ2のtupleでした。
output[0]:__call__メソッドのドキュメントによるとlast_hidden_state。形式は(batch_size, sequence_length, hidden_size)6output[1]:__call__メソッドのドキュメントによるとpooler_output。形式は(batch_size, hidden_size)
output[0](last_hidden_state)からテキストの特徴量が取り出せるようです7(注意:(☆)の記事とは変数の対応を変えています)。
In [11]: last_hidden_states = outputs[0] In [12]: last_hidden_states.shape Out[12]: TensorShape([1, 8, 768])
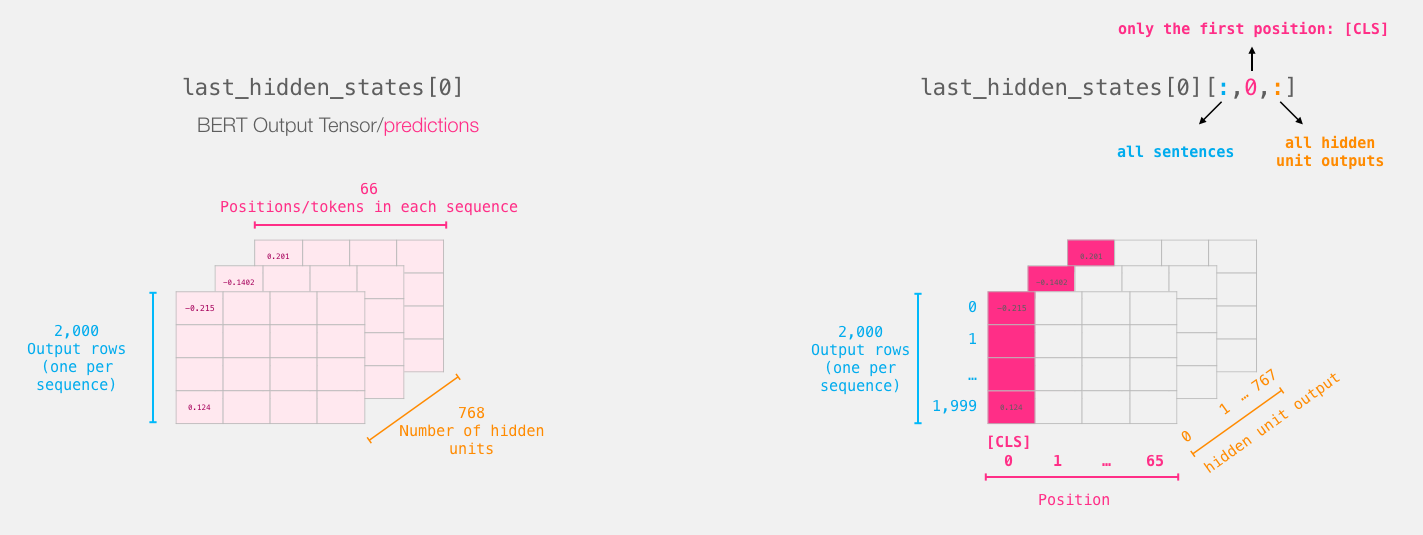
(☆)の記事では、文頭を表す[CLS]を表現したテンソルに興味があるとのことなので、それにならって特徴量を取り出します8(理由が腑に落ちていないので深堀りたいところです)。
numpyメソッドでnumpy.ndarrayとして取り出せます。
In [9]: last_hidden_states[:, 0, :].numpy().shape Out[9]: (1, 768)
こうしてtransformersのサンプルコードの場合は、どのようにすればBERTを使って特徴量が取り出せるのかが分かりました。
なお、以下のIssueも参考になりました。
word or sentence embedding from BERT model · Issue #1950 · huggingface/transformers · GitHub
2.BERTを使ってBBCニュースのテキストを特徴量に変換する
前回使ったBBCニュースのテキスト(2225件)をBERTで特徴量(小数からなるテンソル)に変換します。
コード(bert_feature.py)はこちら:
import csv import tensorflow as tf from transformers import BertTokenizer, TFBertModel tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = TFBertModel.from_pretrained('bert-base-uncased') categories = ['tech', 'business', 'sport', 'entertainment', 'politics'] category_to_id = { category: index for index, category in enumerate(categories) } with open('preprocessed-bbc.csv') as fin: reader = csv.reader(fin) texts_by_ids = [] category_ids = [] for text, category in reader: texts_by_ids.append(tokenizer.encode(text, max_length=512)) category_ids.append(category_to_id[category]) max_len = 0 for input_id_list in texts_by_ids: if len(input_id_list) > max_len: max_len = len(input_id_list) padded_texts_by_ids = [ input_id_list + [0]*(max_len-len(input_id_list)) # 0 padding (テキスト長さ揃える) for input_id_list in texts_by_ids] with open('bert-feature.csv', 'a') as fout: writer = csv.writer(fout) for text_by_ids, category_id in zip(padded_texts_by_ids, category_ids): input_ids = tf.constant([text_by_ids]) output = model(input_ids) last_hidden_states = output[0] feature = last_hidden_states[:, 0, :].numpy() # [CLS]についての全重み writer.writerow(list(feature[0]) + [category_id])
このコードにより、ニュース1つ1つを768の数値からなる1次のテンソルに変換できました。
達成する中でつまづいたのは以下です。
encodeメソッドにmax_length=512と指定する必要があったBertConfigのデフォルト値がモデルに渡っているらしいmodel.configという辞書を確認したところ、'max_position_embeddings'の値は512だったencodeメソッドのmax_length指定により、512語を超えるテキストでもIDに変換されるトークンは512に揃う(先頭から512語が使われている?)
- 2225件のテキストを一度にテンソルに変換しようとしたところ、メモリが足りなくなって落ちた(
Killedの表示)
3.BERTで作った特徴量をもとに分類器を作成
以下のアルゴリズムを試します:
sklearn.LogisticRegressionsklearn.RandomForestClassifier- MLP(
tf.keras.Sequentialで実装)
Accuracyを比較しました:
Accuracy of LogisticRegression: 0.9285393258426966 Accuracy of RandomForestClassifier: 0.835505617977528 Epoch 1/30 1780/1780 [==============================] - 0s 227us/sample - loss: 1.5421 - accuracy: 0.3444 - val_loss: 1.2829 - val_accuracy: 0.5685 : (略) Epoch 30/30 1780/1780 [==============================] - 0s 44us/sample - loss: 0.2793 - accuracy: 0.9084 - val_loss: 0.2423 - val_accuracy: 0.9438
RandomForestClassifierよりLogisticRegressionとMLPのAccuracyが高いという結果になりました。
MLPは、validationデータのAccuracyの方が高いため、30epochでは学習不足なようです(epochを50まで増やしたところ学習不足は変わりませんでした。データが少ないため?)
import csv import numpy as np from sklearn.ensemble import RandomForestClassifier from sklearn.linear_model import LogisticRegression from sklearn.model_selection import cross_val_score import tensorflow as tf from tensorflow.keras import layers with open('bert-feature.csv') as fin: reader = csv.reader(fin) rows = [row for row in reader] features = [list(map(float, row[:-1])) for row in rows] X = np.array(features) category_ids = [int(row[-1]) for row in rows] y = np.array(category_ids) lr = LogisticRegression( multi_class='multinomial', solver='saga', max_iter=100 ) rf = RandomForestClassifier() lr_scores = cross_val_score(lr, X, y, cv=5, scoring='accuracy') print(f'Accuracy of LogisticRegression: {lr_scores.mean()}') rf_scores = cross_val_score(rf, X, y, cv=5, scoring='accuracy') print(f'Accuracy of RandomForestClassifier: {rf_scores.mean()}') # ref: https://qiita.com/ftnext/items/ff9e08e4686d76eddd40 number_of_classes = 5 y = tf.keras.utils.to_categorical(y, number_of_classes) model = tf.keras.Sequential( [ layers.Dense(128, input_shape=(768,), activation=tf.nn.relu), layers.Dropout(0.5), layers.Dense(number_of_classes, activation=tf.nn.softmax), ] ) model.compile( loss="categorical_crossentropy", optimizer=tf.keras.optimizers.Adam(), metrics=["accuracy"], ) history = model.fit( X, y, batch_size=32, epochs=30, verbose=1, validation_split=0.2, )
感想
前回にネタとして挙げた「BERTで特徴量を作ってニューラルネットワークを学習」を達成できました!
BERTで特徴量を作るのにも時間はかかりましたが、一度作って保存しておけば色々なモデルで試せるんですね。
これが「初手BERT時代」。。
現在の状況のキャッチアップに少し手がかかってよかったです🤗(まだまだ高い崖がそびえていますが「これからこれから」ですね)
世はまさにPyTorch時代といった感じで、TensorFlowからBERTを使う情報は少ない印象です。
ですが、手を動かす中で、「特徴量作成は結果をファイルに保存するわけだからTensorFlowでなくてもいい、つまり、情報の多いPyTorchでやってもいい」という気づきを得ました。
自然言語処理ネタで週1ブログはこれで終わりです。
この試みはとてもよくて継続したいのはやまやまなのですが、次のクールは別のことを優先する予定です。
取り組みから離れる前に、できたこと、できなかったことをはっきりさせたいので、振り返り記事を予定しています。
-
encodeメソッドのドキュメントに「Same as doingself.convert_tokens_to_ids(self.tokenize(text))」という記載を見つけ、腑に落ちました。↩ -
BertTokenizerはPreTrainedTokenizerを継承しており、encodeメソッドはPreTrainedTokenizerに定義されています。↩ -
(☆)の図 https://jalammar.github.io/images/distilBERT/bert-distilbert-tokenization-2-token-ids.png が分かりやすいです↩
-
(☆)の図 https://jalammar.github.io/images/distilBERT/bert-model-input-output-1.png が分かりやすいです↩
-
transformersのドキュメントでは、2次のテンソルにするために[None, :]というインデックス指定がされているようです(この書き方についてドキュメントで裏付けが取れていません)。tf.constantのドキュメントを確認し、2次元配列(リストを要素とするリスト)を渡せば、2次のテンソルとなることが分かりました(a = np.array([[1, 2, 3], [4, 5, 6]]))。↩ -
サンプルコードは一文だけのため、
sequence_lengthは文に含まれるトークンの数と等しくなります。複数の文がある場合は各文でトークンの数を揃えるために、パディング埋めする必要があるようです。↩ -
(☆)の図 https://jalammar.github.io/images/distilBERT/bert-output-tensor.png↩
-
(☆)の図 https://jalammar.github.io/images/distilBERT/bert-output-tensor-selection.png↩
{kind=link}
{kind=link}
{kind=link}
{kind=link}