はじめに
「でも、私は天海春香だから。」 nikkieです。
LLM・LangChain関係の素振りですが、今回は自分の趣味嗜好に振り切ります。
文脈をプロンプトに含めて、LLMさんとアニメについておしゃべりするぞ〜!💪💪💪
目次
- はじめに
- 目次
- やりたいこと「文脈をプロンプトに含めたおしゃべり」と、現在地
- 💡素振りに使ったテキスト、アニメ関連のものにすればいいのでは?
- 劇場版『THE IDOLM@STER MOVIE 輝きの向こう側へ!』
- ムビマスを知っている風ChatGPTとおしゃべり
- ムビマスを知っている風LLMの実装例
- 終わりに
やりたいこと「文脈をプロンプトに含めたおしゃべり」と、現在地
準備はすべて整っていたのです!
先日、embeddingsをvector storeに保存し検索する素振りをしました。
- sentence-transformersを使って、embeddingsを計算
- vector storeのChromaに保存
- 入力テキストに類似するテキストを問い合わせる
これにより、少し背伸びをすれば「文脈をプロンプトに含めてLLMに問い合わせる」が実装できる状態です。
以前にも取り組んでいる1のですが、そのときよりも理解が少し深まっています。
差分はRetrieval QA chainを導入するだけ
https://python.langchain.com/docs/modules/chains/popular/vector_db_qapython.langchain.com2
直近の素振りからの背伸びの内訳は以下です:
- ChatGPTを導入する(Chat models3)
- Retrieval QA chainを導入する
- ChatGPTを指定する
- vector storeから
as_retrieverメソッドでretrieverを取得してchainに指定する
コードで示すとこんな感じ。
chat = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) qa = RetrievalQA.from_chain_type( llm=chat, chain_type="stuff", retriever=db.as_retriever() )
💡素振りに使ったテキスト、アニメ関連のものにすればいいのでは?
LangChainのドキュメントではstate_of_the_union.txtを使ったサンプルコードが豊富です。
先の素振りでは、chunk_sizeで分ける代わりに、連続する改行文字("\n\n")で分割して各行を返し、実装を進めました。
類似する行が問合せられています。
そして、閃いてしまったのです。
state_of_the_union.txtのような行で区切られたアニメ関係のテキストを用意できれば、アニメ関係の文脈をプロンプトに含めてLLM(ChatGPT)とお話しできるぞ、と4。
劇場版『THE IDOLM@STER MOVIE 輝きの向こう側へ!』
通称ムビマス5。
今回選んだ理由は、state_of_the_union.txtのようなドキュメントの存在を知っていたからです(Special thanks❤️👏❤️👏)。
かんぺきなさくせんがこちら:
- ムビマスのセリフをembeddingsにして、vector storeに保存する(事前準備)
- ムビマスを踏まえてLLMにテキストを入力をする(私)
- 入力テキストに近いセリフが検索され、プロンプトに含められる(LangChainがサポート)
- LLMはプロンプト(ムビマスの文脈を含む)を元に、応答してくれる!
ムビマスを知っている風ChatGPTとおしゃべり
対話例
LLM(ChatGPT)さんとムビマスについて語ることに成功しましたよ!
— nikkie / にっきー 技書博 け-04 Python型ヒント本 (@ftnext) 2023年7月9日
sentense-transformersでembedding作って、vectorstore (Chroma)を検索させて、以下の会話を実現
>>>もう時間がないんですか
はい、志保さんが言っている通り、時間がない状況のようですね。
ややチートな例ですが、なんか嬉しい🙌 pic.twitter.com/qsisdRfkpp
入力してください: もう時間がないんですか はい、志保さんが言っている通り、時間がない状況のようですね。
志 保 さ ん!!!!6
文脈に入ったのはこのあたり7
- 響「うんうん。まだまだ自分ほどじゃないけどな」
- 志保「もう時間が無いんです! 今進める人間だけでも進まないと、みんなダメになりますよ!?」
- 奈緒「それは今の可奈にはあかんて」
- 響「ふふーん、なんくるないさー!」
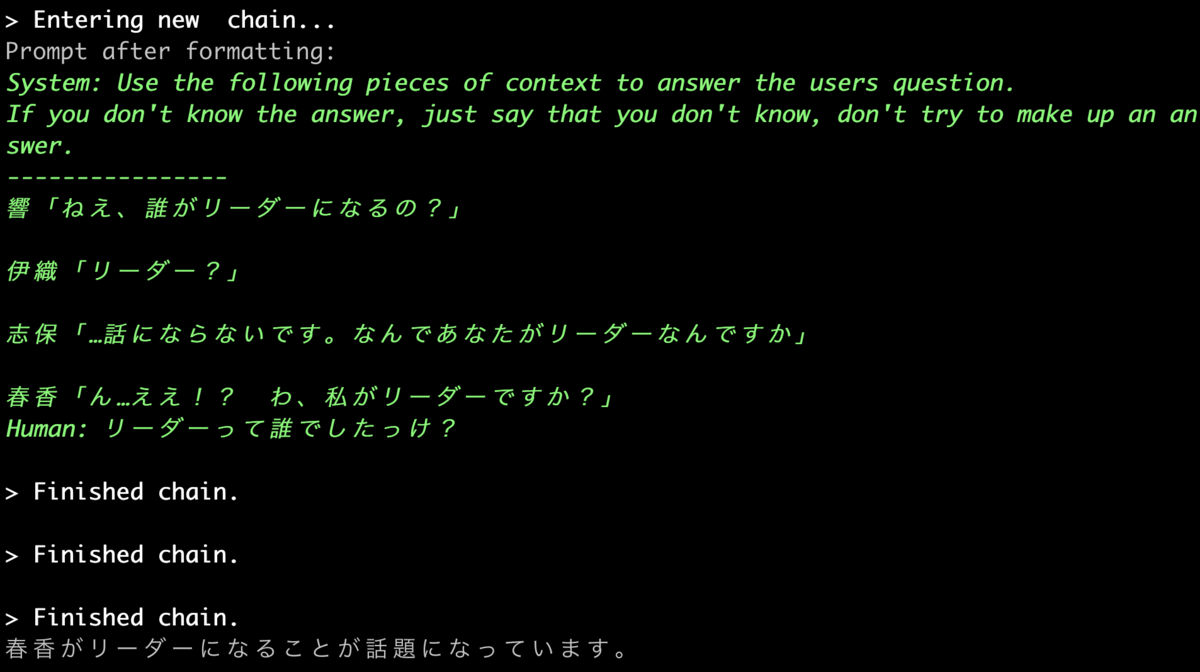
もう一例
入力してください: リーダーって誰でしたっけ? 春香がリーダーになることが話題になっています。
ChatGPTさん、これはもうあなた、ムビマス見てますよね??
文脈に入ったものたち
- 響「ねえ、誰がリーダーになるの?」
- 伊織「リーダー?」
- 志保「…話にならないです。なんであなたがリーダーなんですか」
- 春香「ん…ええ!? わ、私がリーダーですか?」
動作環境
- macOSのCPUで動かしています
- Python 3.10.9
- LangChain 0.0.228
- chromadb 0.3.26
- sentence-transformers 2.2.2
- tqdm 4.65.0
- openai 0.27.8
Chromaの素振り環境の延長で、openaiを追加しました。
環境変数OPENAI_API_KEYを設定済みです。
ムビマスを知っている風LLMの実装例
embeddings保存
state_of_the_union.txtを扱う実装からの違いは、separatorを"\n\n"から"\n"に変えたくらいです。
スクリプトを実行して、ムビマスのembeddingsを保存!
len(documents)=1 len(docs)=1295 100%|████████████████████████████████████████| 1295/1295 [00:00<00:00, 2345260.66it/s]
文脈に含めてChatGPTとおしゃべり
ポイントだと思っているのは
- embeddingsの計算の仕方は揃える(sentence-transformersのstsb-xlm-r-multilingual8)
- vector store(Chroma)をディスクからロード
ChatOpenAIをインスタンス化し、RetrievalQAchainを用意!
行で分割するのは有効なのか?
ムビマス補完計画、ありがたやhttps://t.co/PrbgbALsaE
— nikkie / にっきー 技書博 け-04 Python型ヒント本 (@ftnext) 2023年7月9日
1つのセリフから1つのembeddingを作ってみましたが、チュートリアルでよく見る1000文字(複数文)区切りもありなのかも。
文脈に情報はたくさん込められそう。ピンポイントでベクトルが見つかるか気になるけどOpenAI Embeddingsなら質がいい?
ムビマスの内容と明らかに重なるテキストを入力すると、関連する行が文脈に入り、あたかも知っているように回答できます(リーダーや志保さん)。
行での分割が有効なのかですが、chunk_sizeを指定するよく見る実装のよさにも気づきました。
- vector storeに入っているのが行のembeddingsなので、今回の実装だと文脈に入る情報の量はかなり限定的
- セリフだと前後の文の関わりがありそうなので、document transformerの部分に試行錯誤の余地あり
- 例えば、
CharacterTextSplitter初期化時のchunk_overlap引数を指定して(デフォルト値は2009)のように前の文と重ねるのはありかも(ただし独自実装は必要)
CharacterTextSplitter初期化時にchunk_size=1000(デフォルトは400010)のようにすると、文脈にたくさん情報が入る- ムビマスについてたくさん情報を与えるので、よりムビマスを知っている回答内容を期待できる
- 一方、retrieverが適切な文書を見つけられるかが気になる
今後手を動かして比較してみたいですね。
終わりに
LangChainのRetrievalQAを使って、ムビマスについてアニメガタリしました。
伸びしろの多い実装ですので、こちらから合わせに行く必要はありますが、ムビマスについておしゃべりはできました🙌
以前の素振りと内容としては同じですが、関心のある題材を使え、理解の深まりもあって、たーのしーー!
LLMさんとアニメを話題におしゃべりというのは、過去にも挑戦していました。
今後につながりそうな知見がたまったので、個人的には大満足です!
- ↩
- ドキュメントのバックアップです。https://github.com/hwchase17/langchain/blob/v0.0.228/docs/docs_skeleton/docs/modules/chains/popular/vector_db_qa.mdx ソースコードは https://github.com/hwchase17/langchain/blob/v0.0.228/docs/snippets/modules/chains/popular/vector_db_qa.mdx↩
- ↩
- 別の案としてまどマギも浮かびました。こっちも気になる〜 ↩
- ムビマスからの仕事に関する学びをLTするほどに好きです https://github.com/ftnext/2018_LTslides/blob/2c5f0ea250f816537129cfc2e8c7585d5689a572/aniben_August_imas/PITCHME.md↩
-
志保さんといえば、ダーク・ネクロフィア! この返しめっちゃ好き
— た✿✿ば✿すこ (@mioshu) 2021年1月11日
↩ -
langchain.verbose = Trueを指定しているので、文脈を含んだプロンプトが確認できます。見ていて楽しいです!↩ - 直近の素振りでも試したモデルです。↩
- https://github.com/hwchase17/langchain/blob/v0.0.228/langchain/text_splitter.py#L62↩
- https://github.com/hwchase17/langchain/blob/v0.0.228/langchain/text_splitter.py#L61↩