はじめに
「しらなかった〜1」、nikkieです。
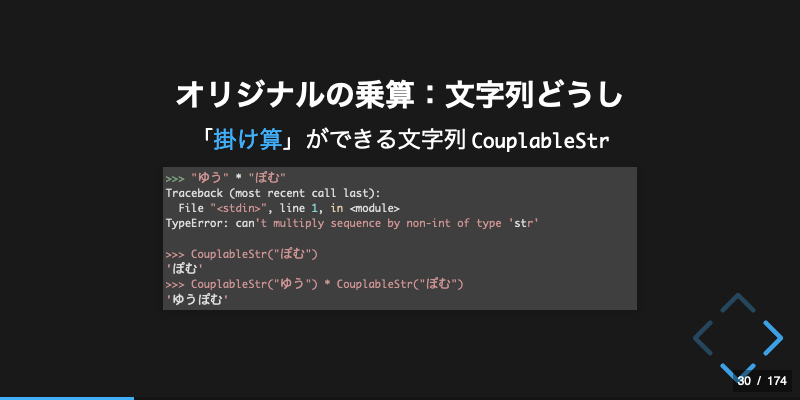
以前、Markdownの「歩夢」を「歩夢🎀」に置き換えるという、どうかしているVS Code拡張を自作しました。
この実装では、VSCode Conference Japan 2021 ハンズオンの基礎編のテキストを大変参考にしています。
先日もアウトプットしましたが、もう一歩、基礎編のテキストの実装の理解が進んだのでアウトプットします。
目次
- はじめに
- 目次
- VSCode APIを駆使してCodeLensを作成する(「ドキュメントを編集しよう」より)
- 登場するVS Code API
- 変数matches(RegExp.execメソッドの返り値)
- VSCode APIを駆使した実装読み解き
- 読み解いた結果、どうかしている拡張のバグも理解
- 終わりに
- P.S. 1/21(土) VSCodeConJPあります!
- 追記(2023/01/19):rangeの取得をよりシンプルに置き換える提案
VSCode APIを駆使してCodeLensを作成する(「ドキュメントを編集しよう」より)
CodeLensProviderのprovideCodeLensesメソッドの実装を見ています。
正規表現を使ってCodeLensを設定する実装はすでに理解しています(先日のアウトプット)。
今回は正規表現にマッチした文字列からCodeLensを作る処理を深堀ります。
while文のところですね。
while ((matches = regex.exec(text)) !== null) { // 見出しが見つかった行を抽出し、 // その範囲をレンジとして切り出す const line = document.lineAt(document.positionAt(matches.index).line); const indexOf = line.text.indexOf(matches[0]); const position = new vscode.Position(line.lineNumber, indexOf); const range = document.getWordRangeAtPosition( position, new RegExp(titleRegex) ); if (range) { // rangeに対するCodeLensを作り、配列codeLensesに追加する(省略) ); } }
登場するVS Code API
while文の後からif文の前までは、以下のAPIを利用しています:
- vscode.TextDocument(
document) - vscode.TextLine(
line)- TextDocumentの1行(ファイルの1行)という理解です
- vscode.Position(
position)- ファイルを開いたVS Codeで、カーソルの置ける位置という理解です
- 何行目の何文字目かを表す
- vscode.Range(
range)- あるPositionから別のPositionまでの範囲という理解です
変数matches(RegExp.execメソッドの返り値)
while ((matches = regex.exec(text)) !== null) {
matches.indexは0 から始める一致した文字列の位置matches[0]は文字が一致した部分の文字列全体
VSCode APIを駆使した実装読み解き
lineの取得
const line = document.lineAt(document.positionAt(matches.index).line);
入り組んでいますが、1つずつ読み解いていきましょう。
document.positionAt(matches.index)は正規表現オブジェクト(titleRegex)に一致した文字が始まるPositionですね。
titleRegexに一致する文字がTextDocumentでは何行目何文字目かを取得します。
Positionのlineプロパティで、何行目かだけ取得しています。
TextDocumentにおける行数が分かったので、lineAtメソッドでその行をTextLineとして取得しました。
lineについてindexOf取得
const indexOf = line.text.indexOf(matches[0]);
TextLineのtextプロパティは、行を表す文字列のようです2。
JavaScriptのString(文字列)のindexOfメソッドを使って、titleRegexに一致した文字列(matches[0])が最初に表れたインデックスを得ます。
その行の中の何文字目からが正規表現と一致する文字列かを知ったわけですね。
positionを作る
const position = new vscode.Position(line.lineNumber, indexOf);
lineの中で正規表現と一致するインデックスの始まり(indexOf)が分かったので、Positionを初期化します。
rangeを取得する
const range = document.getWordRangeAtPosition( position, new RegExp(titleRegex) );
作ったpositionを使って、position以降でtitleRegexに一致する範囲を求めます。
CodeLensの作成は、求めたrangeにコマンドを設定します。
今回コマンドはrangeによらず共通(markdown-date.addDate)ですから、このrangeにコマンドを設定してCodeLensを作ります。
読み解いた結果、どうかしている拡張のバグも理解
「歩夢」を「歩夢🎀」に置き換える自作拡張ですが、「歩夢歩夢」という文字列には以下の動きをします3
現状では、「歩夢歩夢」という行には対応できていません。
コードレンズは2つ表示されるのですが、どちらをクリックしても先の歩夢に🎀追加となりました。
CodeLensが2つ表示されるのは、RegExpインスタンスのexecメソッドでどちらの歩夢もマッチしているからですね。
今回理解が深まったことで、バグの動きになる理由も分かりました。
「歩夢歩夢」なので、取得されるlineとしては2回とも同じです。
lineを取得した後、line.text.indexOf(matches[0])でindexOfを取得する箇所があります。
変数を展開すると以下のコードです。
const indexOf = "歩夢歩夢".indexOf("歩夢");
これって、2回とも同じ値(0)になりますよね。
indexOfメソッドは検索開始位置(fromIndex)を渡す必要があるということですね!
「歩夢歩夢」の行はindexOfが常に0を返すので、作られるCodeLensは2個とも先頭の「歩夢」のrangeに対して作られます。
だから「どちらをクリックしても先の歩夢に🎀追加」となるわけですね。
終わりに
VSCode APIを駆使してCodeLensを作成する実装を読み解きました。
CodeLensの初期化に必要なRangeを正規表現と一致した文字列から取得するのは、けっこう大変なんですね。
マッチした位置が何行目の何文字目かを割り出し、再び正規表現を使ってRangeを取得する、と。
どうかしている拡張実装時はそこまで精読せずに雰囲気で使いましたが、読み解いていく中でバグの理由も分かりました!(後は直すだけ)
P.S. 1/21(土) VSCodeConJPあります!
実は最近のVS Code拡張のアウトプットの背景には、15分に収まりきらないため、1日1エントリに回しているというのがあります。
VSCodeConJP、ハイブリット開催です!
興味深いトークがたくさん4ですので、皆さまよろしければご参加ください!
/
— VS Code Meetup (@vscodejp) 2023年1月17日
📢 1月21(土) 開催
VS Code Conference Japan 2022-2023
スピーカー紹介✨
\
🗣 nikkie (@ftnext)
🔵 楽々入門!VS Codeで『リファクタリング』
🔵 Awakening Extension (拡張開発はじまるよ🔰)
▼参加登録はこちらhttps://t.co/3cHQTA7TLq#vscodejp #vscode pic.twitter.com/QFiCWErBgD
追記(2023/01/19):rangeの取得をよりシンプルに置き換える提案
lineを取得するときにpositionAtメソッドを使っているので、その返り値のpositionを使ってgetWordRangeAtPositionすれば、簡潔な実装に置き換えられるのでは?と気づきました。
- const line = document.lineAt(document.positionAt(matches.index).line); - const indexOf = line.text.indexOf(matches[0]); - const position = new vscode.Position(line.lineNumber, indexOf); + const position = document.positionAt(matches.index); const range = document.getWordRangeAtPosition( position, new RegExp(titleRegex) );
試したところ、これまで通り動き、どうかしている拡張ではバグが解消しました🙌
ハンズオンテキストにプルリクチャンス!
-
引き続きお気に入りのこちらから
↩できる女の「さしすせそ」
— てんわん (@Tenshi_Shitsuzi) 2022年10月8日
さ『さすが〜』
し『しらなかった〜』
す『すご〜い』
せ『せつ菜ちゃんの方が大事なの!?』
そ『そうなんだ〜』 -
型の
stringがAPIのドキュメントにはリンクしていなかったので、「JavaScriptのStringのことなのかな」と理解しました↩ - 引用元はどうかしている拡張自作の記事です(「終わりに」の直前から)↩
- 1/21(土)にハイブリッド開催のVS Code Conference Japan 2022 - 2023、プレイベントのセッション紹介を聞いて、私すごく楽しみなんです! #vscodejp - nikkie-ftnextの日記↩
![JavaScript[完全]入門](https://m.media-amazon.com/images/I/51X+EGiSlYL._SL500_.jpg "JavaScript[完全]入門")