はじめに
評価指標、ばーっといってみよー! nikkieです。
自然言語処理の要約タスクの評価指標に興味を持ち、『大規模言語モデル入門』を参照しました。
要約なので、テキストが生成されるわけです。
これを正解のテキストと比較するわけですが、テキスト同士の定量評価をどうやるのか知りたいと思ったんですね。
目次
- はじめに
- 目次
- 『大規模言語モデル入門』 7.3 要約タスクの評価指標
- BERTScore(7.3.3)
- BERTScore算出の仕組み
- 論文「BERTScore: Evaluating Text Generation with BERT」(わたしのFuture Work)
- 終わりに
『大規模言語モデル入門』 7.3 要約タスクの評価指標
第7章が「要約生成」です。
丁寧に要約生成タスクについて解説されています1(今回は評価指標に強い興味があったので私は積ん読)。
ソースコードはこちらで公開されています:
要約タスクの評価指標として挙げられたのは以下の3つ
- ROUGE
- BLEU
- BERTScore
この記事では、BERTScoreを見ていきます。
ほか2つと異なり、意味を考慮した評価指標という点に惹かれました。
BERTScore(7.3.3)
例として、次の2つのBERTScoreを算出します
- 参照文(正解):「日本語T5モデルの公開」
- 生成文(モデルが生成):「Japanese T5を発表」
環境構築
PyPIで公開されているbert-scoreをインストールします。
合わせてevaluate2(、仕組みの理解用にjapanize-matplotlib)もインストールしました。
- Python 3.10.9
- bert-score==0.3.13
- transformers==4.33.2
- tokenizers==0.13.3
- torch==2.0.1
- numpy==1.26.0
- datasets==2.14.5
- evaluate==0.4.0
- japanize-matplotlib==1.1.3
『大規模言語モデル入門』に沿ってBERTScore算出
>>> import evaluate >>> bertscore = evaluate.load("bertscore") >>> bertscore.add_batch(predictions=["Japanese T5を発表"], references=["日本語T5モデルの公開"]) >>> bertscore.compute(lang="ja") {'precision': [0.8341161608695984], 'recall': [0.7854270935058594], 'f1': [0.8090397119522095], 'hashcode': 'bert-base-multilingual-cased_L9_no-idf_version=0.3.12(hug_trans=4.33.2)'}
公開ソースコードのcompute_bertscore関数の実装を元にしています。
この例の参照文と生成文のBERTScoreは
- Precision: 0.8341161608695984
- Recall: 0.7854270935058594
- F1: 0.8090397119522095
bert-scoreコマンドで算出もできる
PyPIのドキュメントからbert-scoreコマンドの存在を知りました(※書籍の範囲外です)
$ bert-score --lang ja -c 'Japanese T5を発表' -r '日本語T5モデルの公開' bert-base-multilingual-cased_L9_no-idf_version=0.3.12(hug_trans=4.33.2)_fast-tokenizer P: 0.834116 R: 0.785427 F1: 0.809040
-cは--cand(candidate)の短縮、-rは--ref(reference)の短縮です。
上記のPythonコードによる算出結果と一致しますね。
BERTScore算出の仕組み
書籍の図7.6で解説されます。
とても分かりやすかったです
>>> from bert_score import plot_example >>> import japanize_matplotlib # 豆腐対策 >>> plot_example("Japanese T5を発表", "日本語T5モデルの公開", lang="ja")
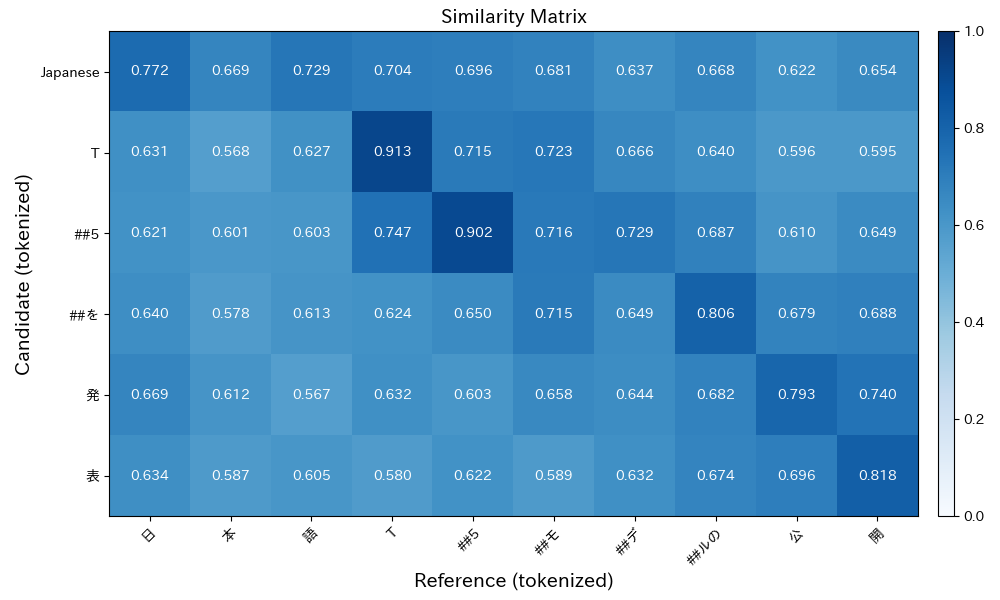
- Precisionはモデルの推論、すなわち生成文(candidate側)です
- matrixを横方向に見ます
- Recallは正解(reference側)です
- matrixを縦方向に見ます
- Precisionの場合は横方向に、各トークンの最大コサイン類似度を取ります
- 0.772 + 0.913 + 0.902 + 0.806 + 0.793 + 0.818
- Recallの場合は縦方向に、各トークンの最大コサイン類似度を取ります
- 0.772 + 0.669 + 0.729 + 0.913 + 0.902 + 0.723 + 0.729 + 0.806 + 0.793 + 0.818
トークン数で割ります。
(間違っているかもしれませんが、)トークンのembeddingの大きさは1です。
文の最大コサイン類似度を1トークンあたりに平均しているという理解です。
- Precision = (0.772 + 0.913 + 0.902 + 0.806 + 0.793 + 0.818) / 6
- = 0.834
- Recall = (0.772 + 0.669 + 0.729 + 0.913 + 0.902 + 0.723 + 0.729 + 0.806 + 0.793 + 0.818) / 10
- = 0.7854
コサイン類似度の小数点以下の桁数を増やせば、上で出した値と一致しそうですね。
F1はPrecisionとRecallから算出されます(いつもの調和平均の式です)
論文「BERTScore: Evaluating Text Generation with BERT」(わたしのFuture Work)
日本語でサマリが読めます。
論文のFigure 1に仕組みが表されています。
この図は『大規模言語モデル入門』の解説内容も含んでいるのですが、より詳しくidfの利用(オプショナル)にも言及しています。
このあたり(3 BERTScore)が積ん読になっています(もっと正確に理解したい!)。
また、「2 Problem statement and prior metrics」では、ROUGEやBLEUなど種々の評価指標が整理されており、(知識のない私には)サーベイ的に読めそうです
終わりに
『大規模言語モデル入門』で知ったBERTScoreを触ってみました。
要約タスクの評価指標として、BERTScoreだけでなくROUGEやBLEUも紹介されていますが、BERTScoreには意味を考慮できるという特徴があります。
書籍に沿ってpip install bert-scoreしてBERTScoreのPrecision, Recall, F1を算出してみました。
手元には参照文・生成文の2文があります。
各文のトークンのembeddingごとのコサイン類似度のmatrixがあり、参照文・生成文それぞれでトークンごとの最大コサイン類似度の平均をとっていると、現段階では理解しています(論文の積ん読を崩したらupdateできそう)