はじめに
みなさんは、死の先には何があると思いますか?
nikkieです。
連休で「Instruction Tuning」を少し調べまして、現時点の理解をまとめます。
※間違ったことを書いていたら@ftnextまでツッコミを入れてください!(お手柔らかにお願いします🙏)
目次
- はじめに
- 目次
- 実は経験のあったInstruction Tuning
- 書籍や資料でインプット
- FLAN論文で提案
- FLANの発展(FLAN T5)
- AlpacaもInstruction Tuningで
- ichikara-instruction!
- この先知りたいこと
- 終わりに
実は経験のあったInstruction Tuning
調べていくうちに、過去に日経Linuxの記事に沿って経験していたと認識しました。
- Instruction Tuningの形式のデータセットを使った
- LLMの重みを全部更新するのではなく、LoRAで外付けした重みだけ更新(※今回PEFTは掘り下げません)
書籍や資料でインプット
今回のインプットによって、断片的に知っていた事項に繋がりが見えてきた気がします。
『大規模言語モデル入門』
「4.4 指示チューニング」を参照。
指示チューニング(instruction tuning)は、指示を含んだプロンプトと理想的な出力テキストの組で構成されるデータセットを使ったファインチューニングによって大規模言語モデルのアライメントを行う方法 (Kindle版 p.140)
松尾研 サマースクール 2023 大規模言語モデル講座 Day5
サマースクールサイトから資料をダウンロードできますが、Day5の資料はSpeaker Deckで公開されています。
様々なタスクがこの入出力形式に内包
FLAN論文で提案
Instruction Tuningの提案論文がこちら1:
Google Research発の論文です。
ここで提案されたモデルがFLAN(Finetuned Language Net)
先行する論文に「Language Models are Few-Shot Learners」(2020)(GPT-3の論文)があり、プロンプトに例(few-shot)を入れることで良い性能を示すことが分かっていました。
Instruction Tuningは、言語モデルのzero-shotでの性能向上手法として提案されます。
「ここ頭いいなー」と思ったんですが、「様々なタスクを指示・回答という形式に統一したデータセット」を用意してるんです!2
日経Linux記事でも指示・回答という形式で作っていました!
### 指示:
{instruction}
### 回答:
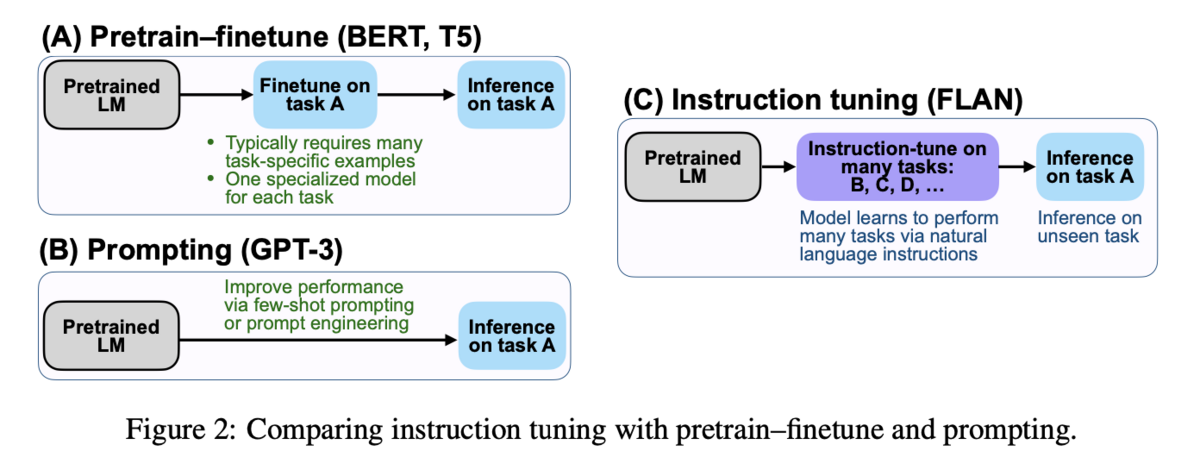
論文からFigure 2を引用します。
Instruction Tuning (C) は、あるタスクのファインチューニング (A) と、few-shotのプロンプト (B) を組み合わせたもの3と言っています。
FLANの発展(FLAN T5)
We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (略). (Abstractより)
FLAN T5というモデルを聞いたことがあったのですが、モデルカード中の画像が論文のFigure 1なんですよね
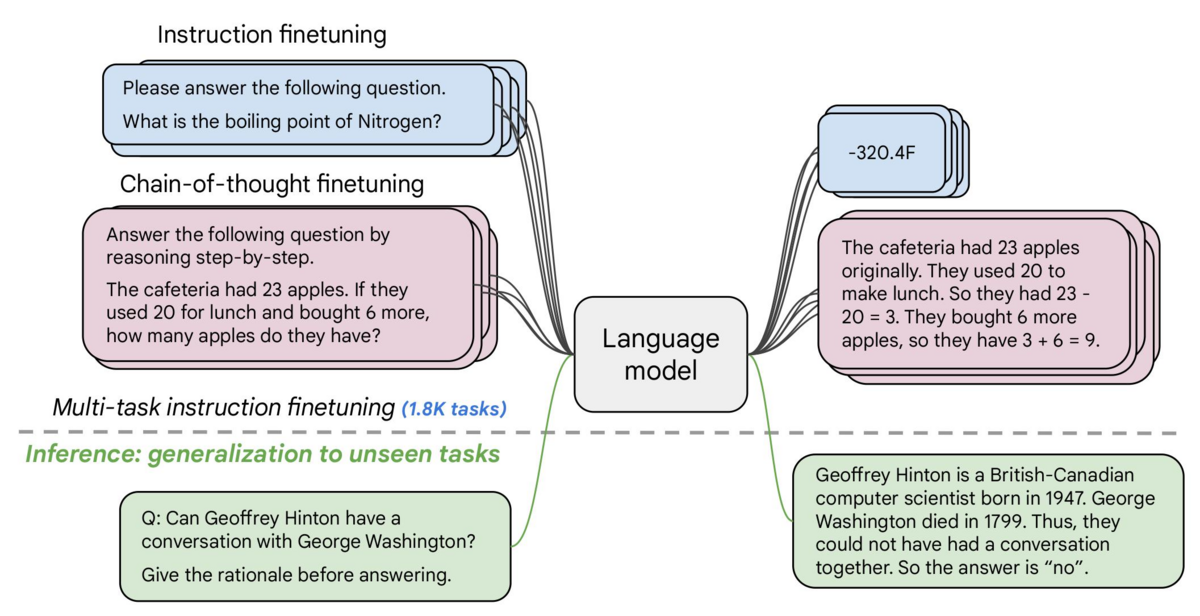
Multi-task instruction tuning(緑)、1.8Kのタスクでデータセットを用意と、めちゃめちゃスケールさせています。
If you already know T5, FLAN-T5 is just better at everything. For the same number of parameters, these models have been fine-tuned on more than 1000 additional tasks covering also more languages.(TL;DRより)
T5を1000を超える追加タスクでファインチューンしたものが、FLAN T5!
AlpacaもInstruction Tuningで
松尾研講座資料の有効性のところに、Alpacaの文字が!
- FLANでZero-shot性能の向上
- Alpacaで指示応答性能の向上
(Alpacaは)Meta社が開発したLLaMA 7BモデルにInstruction Tuningを適用した
https://crfm.stanford.edu/2023/03/13/alpaca.html
ちょうどNLPコロキウムでAlpacaの話を聞いて(正確には聞き流して)おり、「Instruction Tuningでできたモデルだったのか!」となりました。
ichikara-instruction!
NLP2024で複数回耳にしたichikara-instruction(データセット)。
我ながら気づくのが遅すぎたんですが、「各社Instruction Tuningをして(Alpacaのように)日本語での指示応答性能を向上させようとしていたんだなあ」と気づきました。
一例です
この先知りたいこと
次の論文まとめが流れてきました。
LLMを特定タスクに向けてinstruction tuningするときに関連タスクのデータも混ぜると精度向上する事があるが、instructionの文面の Encoder(論文だとSentence Transformer)での埋込のコサイン類似度の高い方から加えると良いタスクを選定できるとのこと。… pic.twitter.com/sdgCVy0vQF
— Tatsuya Shirakawa (@s_tat1204) 2024年4月26日
LLMを特定タスクに向けてinstruction tuningするときに関連タスクのデータも混ぜると精度向上する事があるが、instructionの文面の Encoder(論文だとSentence Transformer)での埋込のコサイン類似度の高い方から加えると良いタスクを選定できるとのこと。
日経Linux記事の例は「Linuxコマンドを答える」という1タスクなのですが、関連タスク(他の質問応答とか?)も混ぜるといいってこと?
Instruction Tuning自体、複数タスク混ぜたデータセットを用意しているわけで、その中から選りすぐって使うというアプローチが提案されているのか〜
終わりに
「Instruction Tuning」で色々な事象が結びつき、ここにアウトプットしました。
- Instruction Tuningはデータセットへのアプローチ。自然言語処理のタスクを指示と回答で同一視して混ぜる
- Instruction Tuningで、言語モデルのzero-shot性能や指示応答性能を向上させられることがわかった
- (言語モデルは、few-shot性能が高いことがわかっていた)
- 日本でもichikara-instruction作成と、それを用いた各社のLLM開発
研究の流れが結びついたことで、Instruction Tuningについて手を動かしたくてうずうずしています。
データセットのアプローチだと思うので、LoRAなどのPEFT手法側からInstruction Tuningもやっているサンプルコードを探してみようかな