はじめに
TikTokerじゃなくて、えぬえるぴーや1なnikkieです。
久しぶりのChatGPTネタです2。
ChatGPT(やLLM)ではトークンの長さに関心が向くことがあります。
そのトークンについて、OpenAI製のライブラリtiktokenの存在を知りました3。
素振りして分かったことをアウトプットします。
目次
tiktokenを知るまで
Chat completionsのGuideを読んでいたnikkie氏。
「Managing tokens」のところを読んでいると...
To see how many tokens are in a text string without making an API call, use OpenAI’s tiktoken Python library.
意訳:テキスト文字列に何個のトークンがあるかをAPIを呼び出さずに知るには、OpenAIのtiktokenPythonライブラリを使ってください
ChatGPTとトークン
上で言及した「Managing tokens」の説明を参照します。
トークンの例(英語)
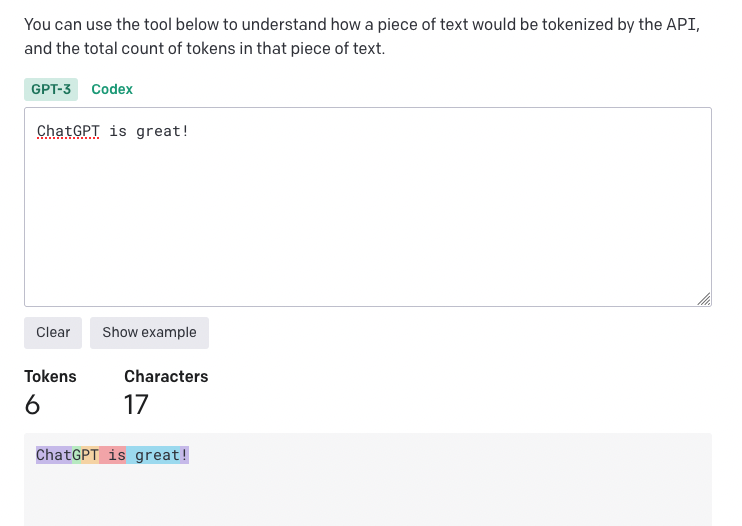
For example, the string "ChatGPT is great!" is encoded into six tokens: ["Chat", "G", "PT", " is", " great", "!"].
意訳: 例えば、"ChatGPT is great!"という文字列は、["Chat", "G", "PT", " is", " great", "!"]と6つのトークンにエンコードされます。
- 英語の場合、トークンは短くて1文字(上の例だと
Gや!)、長くても1単語(great)という理解です4 - (日本語も該当しますが、)いくつかの言語では1文字より短いトークンや1単語より長いトークンがあるそうです5
- ※日本語の場合については
tiktoken素振りのところ(や別記事)で
- ※日本語の場合については
GPT-3向けですが、以下のページでイメージもつかめそうに思います。
https://platform.openai.com/tokenizer
入出力するトークンに課金
gpt-3.5-turbo $0.002 / 1K tokens
ref: https://openai.com/pricing 「Chat」の項目
For example, if your API call used 10 tokens in the message input and you received 20 tokens in the message output, you would be billed for 30 tokens.
意訳:例えば、入力messageに10トークンを使ってあなたがAPIを呼び出し、出力messageとして20トークンを受け取ったならば、あなたは30トークン(=10+20)分の料金を支払う
ChatGPTのモデルに一番近い入出力はトークンで、モデルに出入りするトークンに課金しているのかなと私はとらえています。
入力・出力・合計のトークン数は、APIの返り値でも確認できます。
https://platform.openai.com/docs/guides/chat/response-format
{ "usage": {"prompt_tokens": 56, "completion_tokens": 31, "total_tokens": 87} }
費用を気にする場合、入力するトークン数は、少ない文字数を心がけることになるんでしょうか。
ただ、前のやり取りをChatGPTに踏まえさせる場合、前のやり取りを全部含めてAPIに送ると理解している6ので、入力するトークン数はどんどん増えていき、費用を削減するのは難しそうな印象です。
出力トークン数の制御
出力トークン数については、APIのリクエスト中のオプショナルパラメタmax_tokensに整数値で指定できます。
APIリファレンスを確認すると、このパラメタのデフォルト値はinf(無限大)、
https://platform.openai.com/docs/api-reference/chat/create
つまり制限ないと指定したことになるわけですね(知らず知らずのうちに気前よく支払う設定をされていた!)
tiktoken素振りはじめ
ドキュメントの「Managing tokens」で案内されたcookbookの「How to count tokens with tiktoken」ノートブックを参照しました。
ライブラリ自体はpip install tiktokenでインストールできます。
動作環境
- Python 3.10.9
- tiktoken 0.3.3
Encodingインスタンスを取得
encodingとは、テキストをどのようにトークンに変換するかを定義するもので、モデルによって違うそうです7。
tiktoken.encoding_for_model8でモデル名からEncodingを読み込みます。
ChatGPTのモデル名はgpt-3.5-turboですね。
>>> import tiktoken >>> encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
テキストをトークンにエンコード(encoding.encode)
取得したEncodingのencodeメソッド9を使います。
トークンのID(整数)が並んだリストが返ります。
>>> encoding.encode("tiktoken is great!") [83, 1609, 5963, 374, 2294, 0]
encodeメソッドの返り値(リスト)の長さがポイント!
これが、ChatGPTのAPIでモデルに入力されるトークン長です(すなわち、課金の対象ですね)。
日本語テキストを入れた場合も、同様にトークンのIDが返ります。
>>> encoding.encode("お誕生日おめでとう") # 9トークンと分かりました [33334, 45918, 243, 21990, 9080, 33334, 62004, 16556, 78699]
トークンからテキストにデコード(encoding.decode_tokens_bytes)
トークンのID列からテキストに戻すのは、Encodingのdecodeメソッド10です。
>>> encoding.decode([83, 1609, 5963, 374, 2294, 0]) 'tiktoken is great!'
ここまで来ると、テキストのどの語や文字で1トークンなのか気になりませんか?
トークンの分割はdecode_tokens_bytesメソッド11で見られます。
>>> encoding.decode_tokens_bytes([83, 1609, 5963, 374, 2294, 0]) [b't', b'ik', b'token', b' is', b' great', b'!']
対話モードではbytesはbが付いた文字列で表されます。
ここから「t/ik/token/ is/ great/!」と分割されていることが分かりました!(英語テキストの場合は空白込みでトークンに分割されるのか〜)
日本語の場合、bytesの表示はそのままでは読み解けません。
(続くツイートのように対応が取れるのですが、これは別記事にしようと思います)
>>> encoding.decode_tokens_bytes(encoding.encode("お誕生日おめでとう")) [b'\xe3\x81\x8a', b'\xe8\xaa', b'\x95', b'\xe7\x94\x9f', b'\xe6\x97\xa5', b'\xe3\x81\x8a', b'\xe3\x82\x81', b'\xe3\x81\xa7', b'\xe3\x81\xa8\xe3\x81\x86']
TikTokデビューならぬ、tiktokenデビューしました✌️
— nikkie にっきー (@ftnext) 2023年4月22日
openai製のライブラリでAPIに送らなくてもトークン長が分かります。レッツパーリー⤴️
「お誕生日おめでとう」は9トークン
0 お
1-2 誕 # <- 1文字を2トークン!
3 生
4 日
5 お
6 め
7 で
8 とう # <- 2文字で1トークン!https://t.co/RPB7185TJq
入力するトークン長を数える
ノートブックの「6. Counting tokens for chat API calls」を写経します。
ChatGPT(gpt-3.5-turbo)の場合のトークン長の計算はこちら:
根本にあるのは、encodeメソッドの返り値(=トークン数)を数える実装です。
ChatGPTのAPIには一度に複数のmessageを送れます(前のやり取りも合わせて送る話題を出しましたね)。
ChatGPTでは、各messageは<|start|>{role/name}\n{content}<|end|>\nという形式になるようで、messageごとに4トークン追加します(tokens_per_message = 4)。
ただし、nameがある場合は、roleが除かれるそうで(つまり、3トークン)、num_tokensから1トークン減らすために tokens_per_name = -1 としています。
ノートブックでは、ChatGPTのAPI呼び出しでmax_tokens=1を指定し、入力したトークンを数えさせているだけです。
response["usage"]["prompt_tokens"]とnum_tokens_from_messagesの返り値が等しいことを確認しています。
ここで検証してくれているので、私たちはtiktokenでトークン数を数えるだけで、何トークン入力するかが分かりますね!
終わりに
APIを呼び出さなくてもトークン長が分かるtiktokenを知り、素振りしました。
Encodingを取得し、テキストをトークンにencode、トークンからテキストにdecodeできます。
入力するトークン長を見える化し、出力のトークン長はmax_lengthで指定することで、お財布にやさしくChatGPTを触っていけそうですね!
検証するときは倹約モードでコストカットし、価値が出そうと分かったら節約は考えずアクセルを踏み込めばいいんじゃないかな〜と思ってます(かつてソシャゲイベで走ったときと似ているかも!)
ChatGPTってブラックボックスでしたが、中ではtiktokenのようにテキストからトークン(ID)への変換が走っていると知り、「BERTなど知ってる他の言語モデルっぽいな」と思いました。
ChatGPT(やLLM)もWord embeddings12を持っているってことですね。
P.S. gpt-3.5-turbo-0301って何?
「How to count tokens with tiktoken」ノートブックの中で目にしたのが、gpt-3.5-turboだけでなくgpt-3.5-turbo-0301。
ドキュメントの以下を見て、何なのかが分かりました。
https://platform.openai.com/docs/models/gpt-3-5
APIの/v1/chat/completionsでは、モデルにgpt-3.5-turboもgpt-3.5-turbo-0301も指定できます13。
gpt-3.5-turbo- ChatGPT用モデルで常に最新
gpt-3.5-turbo-0301- 2023/03/01時点の
gpt-3.5-turboのスナップショット - アップデートは受け取らない
- 2023/03/01時点の
gpt-3.5-turboはアップデートされますが、gpt-3.5-turbo-0301されません。
アップデート=改善だと思うので、私の意見としてはgpt-3.5-turboを常に指定したいです。
もちろん、結果を確実に再現させるために、改善を受け取る前のモデル(スナップショットgpt-3.5-turbo-0301)を指定することもあると思います
- NLPer(自然言語処理する人)↩
- アメリカ行けなかった代わりに得たタスクに追われる感のないお休みなのです。お決まりの「こころはやってんの、ChatGPT?」↩
- OpenAIがtiktokenと命名していなかったら、私もこんなにTikTokと絡めなかったでしょう↩
- ref: In English, a token can be as short as one character or as long as one word↩
- ref: in some languages tokens can be even shorter than one character or even longer than one word.↩
- ref: 「また、ChatGPT は記憶を持たないので、対話をするにはリクエストに"user"の発言だけではなく"assistant"との対話の履歴を含める必要がある点には注意してください。」 (この記事はChatGPTでできることをつかむのにオススメです!)↩
- 「How to count tokens with tiktoken」の「Encodings」より 「Encodings specify how text is converted into tokens. Different models use different encodings.」↩
- https://github.com/openai/tiktoken/blob/0.3.3/tiktoken/model.py#L56-L75↩
- https://github.com/openai/tiktoken/blob/0.3.3/tiktoken/core.py#L75-L129↩
- https://github.com/openai/tiktoken/blob/0.3.3/tiktoken/core.py#L242-L254↩
- https://github.com/openai/tiktoken/blob/0.3.3/tiktoken/core.py#L270-L277↩
- Word Embeddings: Encoding Lexical Semantics — PyTorch Tutorials 2.0.0+cu117 documentationが分かりやすかったです↩
- ref: https://platform.openai.com/docs/models/model-endpoint-compatibility↩