はじめに
バーン! nikkieです。
小さなネタではあるのですが、アハ体験があったので記します。
目次
「Kubeflow Pipelines v2 で変わる機械学習パイプライン開発」
2024/03/20 第39回 MLOps 勉強会の資料を後追いしていました。
杉山さんがKubeflow Pipelines v2の発表をされていて、その中で目を引いたのがこちら
至るまでの流れとしては
の後にこちらのアップロードです。
過去にKubeflow Pipelinesを触っていて、kfpも知っていました。
私の中では、kfpを使ってPythonファイルにDSLを書き、そこからYAMLファイルに変換して、それをKubeflow Pipelinesにアップロードという理解でした。
ここにYAMLファイルをGoogle CloudのVertex AI Pipelinesにアップロードしてもよいという選択肢が示されたのです!
k8sクラスタ(Kubeflow)が要るものと思い込んでいたので、目からウロコでした。
マネージドサービスってすげ〜
Hello Worldを試す
- Python 3.11.4
pip install kfp- 2系をインストール(2.7.0が入りました)
ライブラリバージョン
cachetools==5.3.3 certifi==2024.2.2 charset-normalizer==3.3.2 click==8.1.7 docstring_parser==0.16 google-api-core==2.18.0 google-auth==2.29.0 google-cloud-core==2.4.1 google-cloud-storage==2.16.0 google-crc32c==1.5.0 google-resumable-media==2.7.0 googleapis-common-protos==1.63.0 idna==3.6 kfp==2.7.0 kfp-pipeline-spec==0.3.0 kfp-server-api==2.0.5 kubernetes==26.1.0 oauthlib==3.2.2 proto-plus==1.23.0 protobuf==4.25.3 pyasn1==0.6.0 pyasn1_modules==0.4.0 python-dateutil==2.9.0.post0 PyYAML==6.0.1 requests==2.31.0 requests-oauthlib==2.0.0 requests-toolbelt==0.10.1 rsa==4.9 six==1.16.0 tabulate==0.9.0 urllib3==1.26.18 websocket-client==1.7.0
Google Cloudは、過去に以下の記事で素振りした跡地プロジェクトを再利用しました。
スクリプトを実行して生成されたYAMLファイルを、アップロードします!
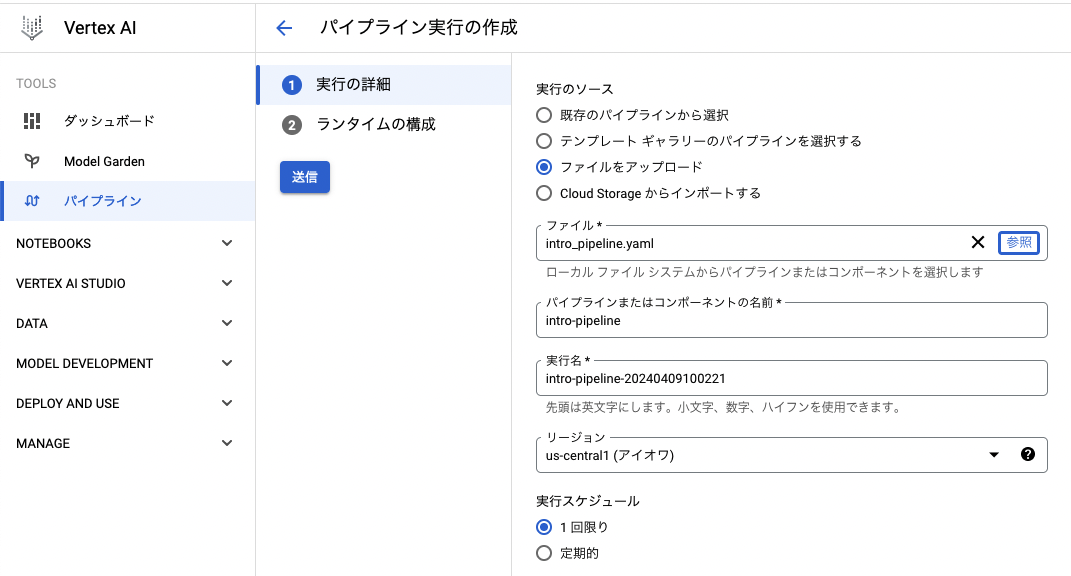
Runが作られ、実行されました🙌

見事な整理
杉山さんのスライド、用語の整理が見事でした👏
KubeflowとVertex AIが根っこは同じと理解しました
この整理があったので、kfpがcompileして出力するYAMLファイルが、Kubeflow Pipelinesにも、Vertex AI Pipelinesにも使えるという点をスルーせずに気づけました。
残された宿題
過去に触ったkfpは1.8系でした。
過去記事に沿ったYAMLファイルを当初Vertex AI Pipelinesにアップロードしたのですが、これは弾かれてしまいます。
ファイルの内容が無効です
kfp v2への移行が必要なのかなと考えていて、杉山さんの記事を元に手を動かしてみたいです。
(これができると手元の既存の資産をVertex AI Pipelinesでも動かせる世界が来るので!)
終わりに
KubeflowとVertex AIって理解がぐちゃぐちゃだったのですが、第39回 MLOps 勉強会の発表資料のおかげで、Kubeflow Pipelinesを少し触った地点からVertex AI Pipelinesに至る道が見えました!


